
May 26, 2022
Building a Bulk Asynchronous Bird Recipient Validation Tool
One of the questions we occasionally receive is, how can I bulk validate email lists with Empfänger-Validierung? There are two options here, one is to upload a file through the SparkPost UI for validation, and the other is to make individual calls per email zum API (as the API is single email validation).
Die erste Option funktioniert gut, hat aber eine Beschränkung auf 20 MB (etwa 500.000 Adressen). Was ist, wenn jemand eine E-Mail-Liste mit Millionen von Adressen hat? Das könnte bedeuten, dass man die Liste in 1.000 CSV-Dateien aufteilen muss, die hochgeladen werden.
Since uploading thousands of CSV files seems a little far-fetched, I took that use case and began to wonder how fast I could get the API to run. In this blog post, I will explain what I tried and how I eventually came to a program that could get around 100.000 Überprüfungen in 55 Sekunden (Whereas in the UI I got around 100,000 validations in 1 minute 10 seconds). And while this still would take about 100 hours to get done with about 654 million validations, this script can run in the background saving significant time.
Die endgültige Version dieses Programms finden Sie unter here.
Mein erster Fehler: Python verwenden
Python ist eine meiner Lieblings-Programmiersprachen. Sie zeichnet sich in vielen Bereichen aus und ist unglaublich einfach zu handhaben. Ein Bereich, in dem sie sich jedoch nicht auszeichnet, sind nebenläufige Prozesse. Python hat zwar die Möglichkeit, asynchrone Funktionen auszuführen, aber es gibt das so genannte Python Global Interpreter Lock oder GIL.
"Das Python Global Interpreter Lock oder GIL ist, einfach ausgedrückt, ein Mutex (oder ein Lock), das es nur einem Thread erlaubt, die Kontrolle über den Python-Interpreter zu behalten.
Dies bedeutet, dass sich zu jedem Zeitpunkt nur ein Thread in einem Ausführungszustand befinden kann. Die Auswirkungen der GIL sind für Entwickler, die Single-Thread-Programme ausführen, nicht sichtbar, können aber bei CPU-gebundenem und Multi-Thread-Code einen Leistungsengpass darstellen.
Since the GIL allows only one thread to execute at a time even in a multi-threaded architecture with more than one CPU core, the GIL has gained a reputation as an “infamous” feature of Python.” (https://realpython.com/python-gil/)”
Zunächst war ich mir der GIL nicht bewusst, also begann ich mit der Programmierung in Python. Am Ende, obwohl mein Programm asynchron war, wurde es blockiert, und egal wie viele Threads ich hinzufügte, ich bekam immer noch nur etwa 12-15 Iterationen pro Sekunde.
Der Hauptteil der asynchronen Funktion in Python ist unten zu sehen:
async def validateRecipients(f, fh, apiKey, snooze, count): h = {'Authorization': apiKey, 'Accept': 'application/json'} with tqdm(total=count) as pbar: async with aiohttp.ClientSession() as session: for address in f: for i in address: thisReq = requests.compat.urljoin(url, i) async with session.get(thisReq,headers=h, ssl=False) as resp: content = await resp.json() row = content['results'] row['email'] = i fh.writerow(row) pbar.update(1)
Also habe ich die Verwendung von Python verworfen und bin zurück zum Zeichenbrett gegangen...
Ich entschied mich für die Verwendung von NodeJS aufgrund seiner Fähigkeit, nicht-blockierende E/A-Operationen extrem gut durchzuführen. Ich bin auch ziemlich vertraut mit der Programmierung in NodeJS.
Utilizing asynchronous aspects of NodeJS, this ended up working well. For more details about asynchronous programming in NodeJS, see https://blog.risingstack.com/node-hero-async-programming-in-node-js/
Mein zweiter Fehler: der Versuch, die Datei in den Speicher zu lesen
Meine ursprüngliche Idee war die folgende:
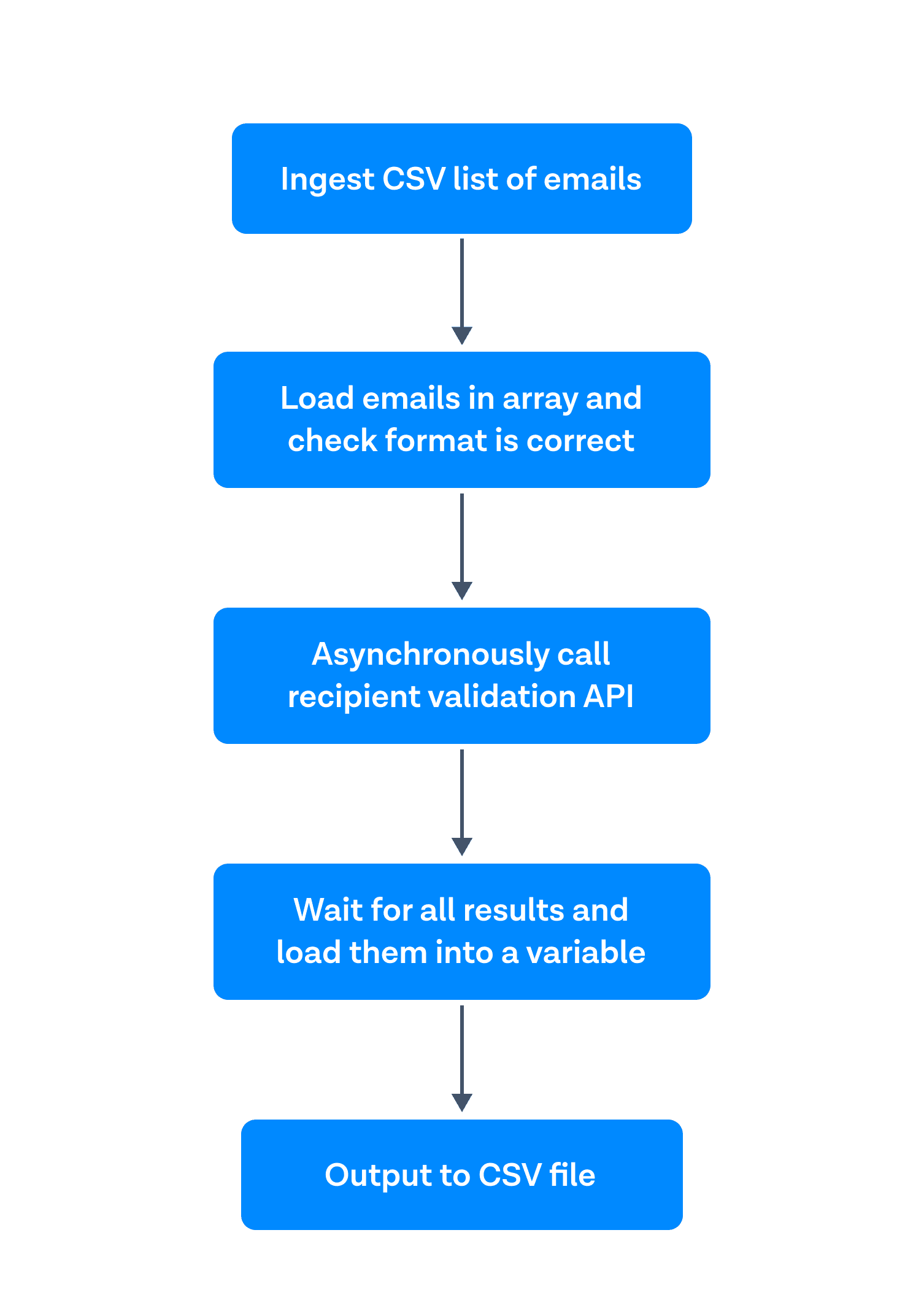
Erstens: Einlesen einer CSV-Liste mit E-Mails. Zweitens: Laden Sie die E-Mails in ein Array und überprüfen Sie, ob sie das richtige Format haben. Drittens: Asynchroner Aufruf der Empfängervalidierungs-API. Viertens: Warten Sie auf die Ergebnisse und laden Sie sie in eine Variable. Und schließlich geben Sie diese Variable in eine CSV-Datei aus.
This worked very well for smaller files. Die issue became when I tried to run 100,000 emails through. Die program stalled at around 12,000 validations. With the help of one of our front-end developers, I saw that the issue was with loading all the results into a variable (and therefore running out of memory quickly). If you would like to see the first iteration of this program, I have linked it here: Version 1 (NICHT EMPFOHLEN).
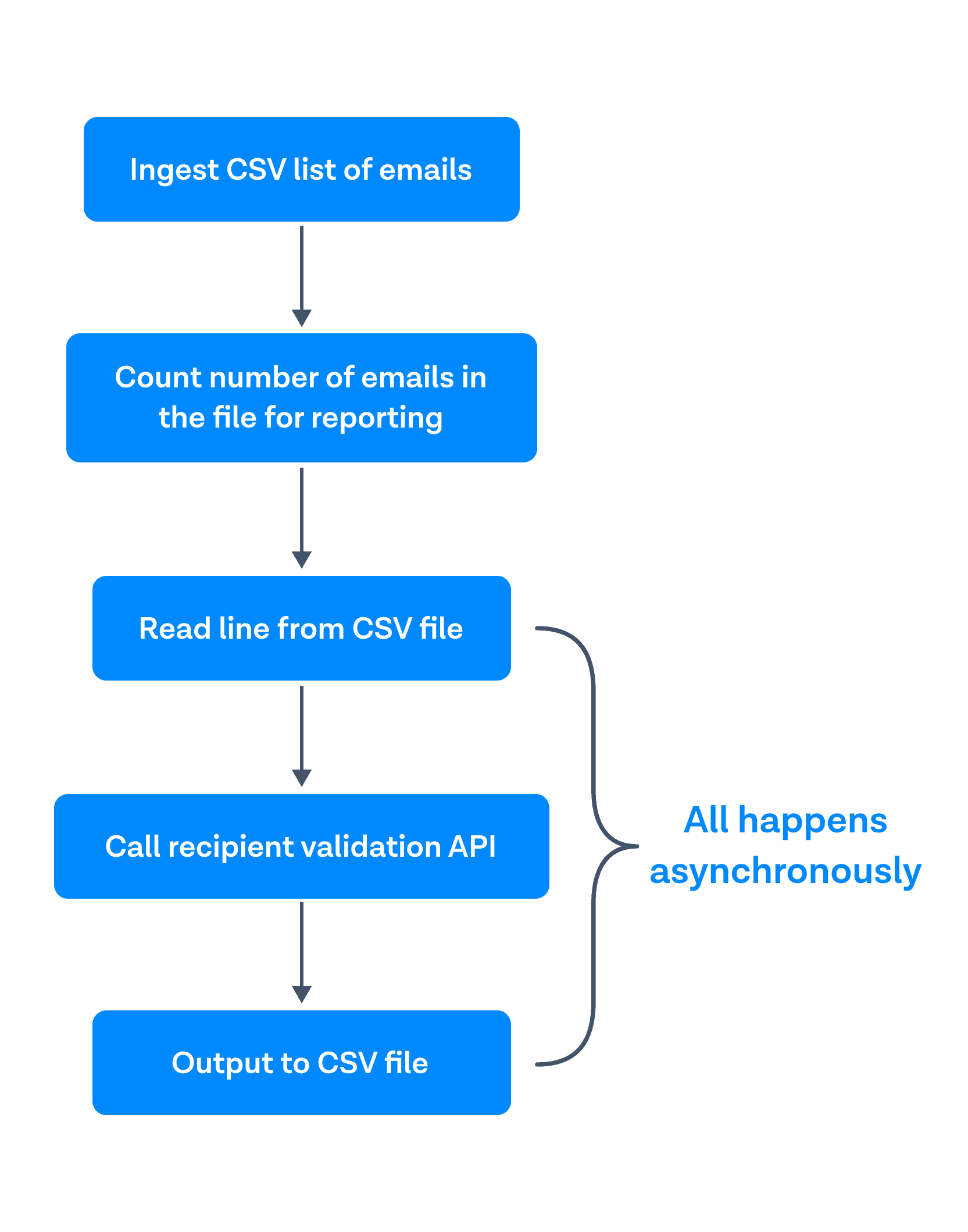
Zuerst nehmen Sie eine CSV-Liste mit E-Mails auf. Zweitens: Zählen Sie die Anzahl der E-Mails in der Datei für Berichtszwecke. Drittens rufen Sie beim asynchronen Lesen jeder Zeile die API für die Empfängervalidierung auf und geben die Ergebnisse in eine CSV-Datei aus.
Daher rufe ich für jede eingelesene Zeile die API auf und schreibe die Ergebnisse asynchron aus, um keine dieser Daten im Langzeitspeicher zu halten. Ich habe auch die Prüfung der E-Mail-Syntax entfernt, nachdem ich mit dem Team für die Empfängervalidierung gesprochen hatte, da sie mir mitteilten, dass die Empfängervalidierung bereits Prüfungen eingebaut hat, um zu prüfen, ob eine E-Mail gültig ist oder nicht.
Aufschlüsselung des endgültigen Codes
Nachdem ich die Terminalargumente eingelesen und validiert habe, führe ich den folgenden Code aus. Zunächst lese ich die CSV-Datei mit den E-Mails ein und zähle jede Zeile. Diese Funktion dient zwei Zwecken: 1) Sie ermöglicht es mir, genaue Berichte über den Fortschritt der Datei zu erstellen [wie wir später sehen werden], und 2) sie ermöglicht es mir, einen Timer zu stoppen, wenn die Anzahl der E-Mails in der Datei den abgeschlossenen Validierungen entspricht. Ich habe einen Timer hinzugefügt, damit ich Benchmarks durchführen und sicherstellen kann, dass ich gute Ergebnisse erhalte.
let count = 0; //Line count require("fs") .createReadStream(myArgs[1]) .on("data", function (chunk) { for (let i = 0; i < chunk.length; ++i) if (chunk[i] == 10) count++; }) //Reads the infile and increases the count for each line .on("close", function () { //At the end of the infile, after all lines have been counted, run the recipient validation function validateRecipients.validateRecipients(count, myArgs); });
Dann rufe ich die Funktion validateRecipients auf. Beachten Sie, dass diese Funktion asynchron ist. Nachdem ich überprüft habe, dass es sich bei infile und outfile um CSV-Dateien handelt, schreibe ich eine Kopfzeile und starte einen Programm-Timer mit der JSDOM-Bibliothek.
async function validateRecipients(email_count, myArgs) { if ( //If both the infile and outfile are in .csv format extname(myArgs[1]).toLowerCase() == ".csv" && extname(myArgs[3]).toLowerCase() == ".csv" ) { let completed = 0; //Counter for each API call email_count++; //Line counter returns #lines - 1, this is done to correct the number of lines //Start a timer const { window } = new JSDOM(); const start = window.performance.now(); const output = fs.createWriteStream(myArgs[3]); //Outfile output.write( "Email,Valid,Result,Reason,Is_Role,Is_Disposable,Is_Free,Delivery_Confidence\n" ); //Write the headers in the outfile
Das folgende Skript ist eigentlich der größte Teil des Programms, daher werde ich es aufteilen und erklären, was passiert. Für jede Zeile der Infodatei:
Asynchronously take that line and call the Empfänger-Validierungs-API.
fs.createReadStream(myArgs[1]) .pipe(csv.parse({ headers: false })) .on("data", async (email) => { let url = SPARKPOST_HOST + "/api/v1/recipient-validation/single/" + email; await axios .get(url, { headers: { Authorization: SPARKPOST_API_KEY, }, }) //For each row read in from the infile, call the SparkPost Recipient Validation API
Dann, auf die Antwort
Fügen Sie die E-Mail zum JSON hinzu (um die E-Mail in der CSV-Datei ausdrucken zu können)
Prüfen Sie, ob der Grund null ist, und wenn ja, geben Sie einen leeren Wert ein (dies dient der Konsistenz des CSV-Formats, da in einigen Fällen der Grund in der Antwort angegeben wird).
Legen Sie die Optionen und Schlüssel für das json2csv-Modul fest.
Konvertierung von JSON in CSV und Ausgabe (mit json2csv)
Schreibfortschritt im Terminal
Wenn die Anzahl der E-Mails in der Datei gleich der Anzahl der abgeschlossenen Überprüfungen ist, wird der Timer gestoppt und die Ergebnisse werden ausgedruckt.
.then(function (response) { response.data.results.email = String(email); //Adds the email as a value/key pair zum response JSON to be used for output response.data.results.reason ? null : (response.data.results.reason = ""); //If reason is null, set it to blank so the CSV is uniform //Utilizes json-2-csv to convert the JSON to CSV format and output let options = { prependHeader: false, //Disables JSON values from being added as header rows for every line keys: [ "results.email", "results.valid", "results.result", "results.reason", "results.is_role", "results.is_disposable", "results.is_free", "results.delivery_confidence", ], //Sets the order of keys }; let json2csvCallback = function (err, csv) { if (err) throw err; output.write(`${csv}\n`); }; converter.json2csv(response.data, json2csvCallback, options); completed++; //Increase the API counter process.stdout.write(`Done with ${completed} / ${email_count}\r`); //Output status of Completed / Total to the console without showing new lines //If all emails have completed validation if (completed == email_count) { const stop = window.performance.now(); //Stop the timer console.log( `All emails successfully validated in ${ (stop - start) / 1000 } seconds` ); } })
Ein letztes Problem, das ich fand, war, dass dies zwar auf dem Mac gut funktionierte, ich aber unter Windows nach etwa 10.000 Validierungen auf den folgenden Fehler stieß:
Fehler: Verbindung ENOBUFS XX.XX.XXX.XXX:443 - Local (undefined:undefined) mit E-Mail XXXXXXX@XXXXXXXXXX.XXX
After doing some further research, it appears to be an issue with the NodeJS HTTP client connection pool not reusing connections. I found this Stackoverflow-Artikel on the issue, and after further digging, found a good Standardkonfiguration for the axios library that resolved this issue. I am still not certain why this issue only happens on Windows and not on Mac.
Nächste Schritte
Wenn Sie ein einfaches, schnelles Programm suchen, das eine CSV-Datei aufnimmt, die API für die Empfängervalidierung aufruft und eine CSV-Datei ausgibt, ist dieses Programm genau das Richtige für Sie.
Einige Ergänzungen zu diesem Programm wären folgende:
Erstellung eines Frontends oder einer einfacheren UI für die Nutzung
Bessere Fehler- und Wiederholungsbehandlung, denn wenn die API aus irgendeinem Grund einen Fehler auslöst, versucht das Programm den Aufruf derzeit nicht erneut.
Ich wäre auch neugierig zu sehen, ob mit einer anderen Sprache wie Golang oder Erlang/Elixir schnellere Ergebnisse erzielt werden könnten.
Please feel free to provide me any Feedback oder Vorschläge for expanding this project.